DMA 傳輸(Direct Memory Access,直接記憶體存取)是嵌入式系統中不可或缺的資料搬運技術。它允許周邊設備直接與記憶體交換資料,無需 CPU 逐字節干預——這在 ADC 連續取樣、SPI 高速通訊、UART 大量資料收發等高吞吐量場景中至關重要。
本文從 DMA 傳輸的硬體架構出發,深入解析 DMA 控制器的工作原理、傳輸模式、配置流程,並以 STM32 和 ESP32 為平台展示完整的程式實作。
什麼是 DMA?為什麼需要它?
在傳統的程式 I/O 模式中,CPU 必須逐字節/逐字地從周邊讀取資料並寫入記憶體。這意味著:
- CPU 被「綁架」在資料搬運上,無法執行其他任務
- 高頻率的資料傳輸(如 ADC 1MSps)會耗盡 CPU 頻寬
- 即時性任務(控制迴路、通訊協定)可能因此延遲
DMA 控制器相當於一個專門的「資料搬運引擎」,它可以在背景獨立完成記憶體↔周邊的資料傳輸,只在傳輸完成或發生錯誤時通知 CPU。

DMA 控制器架構
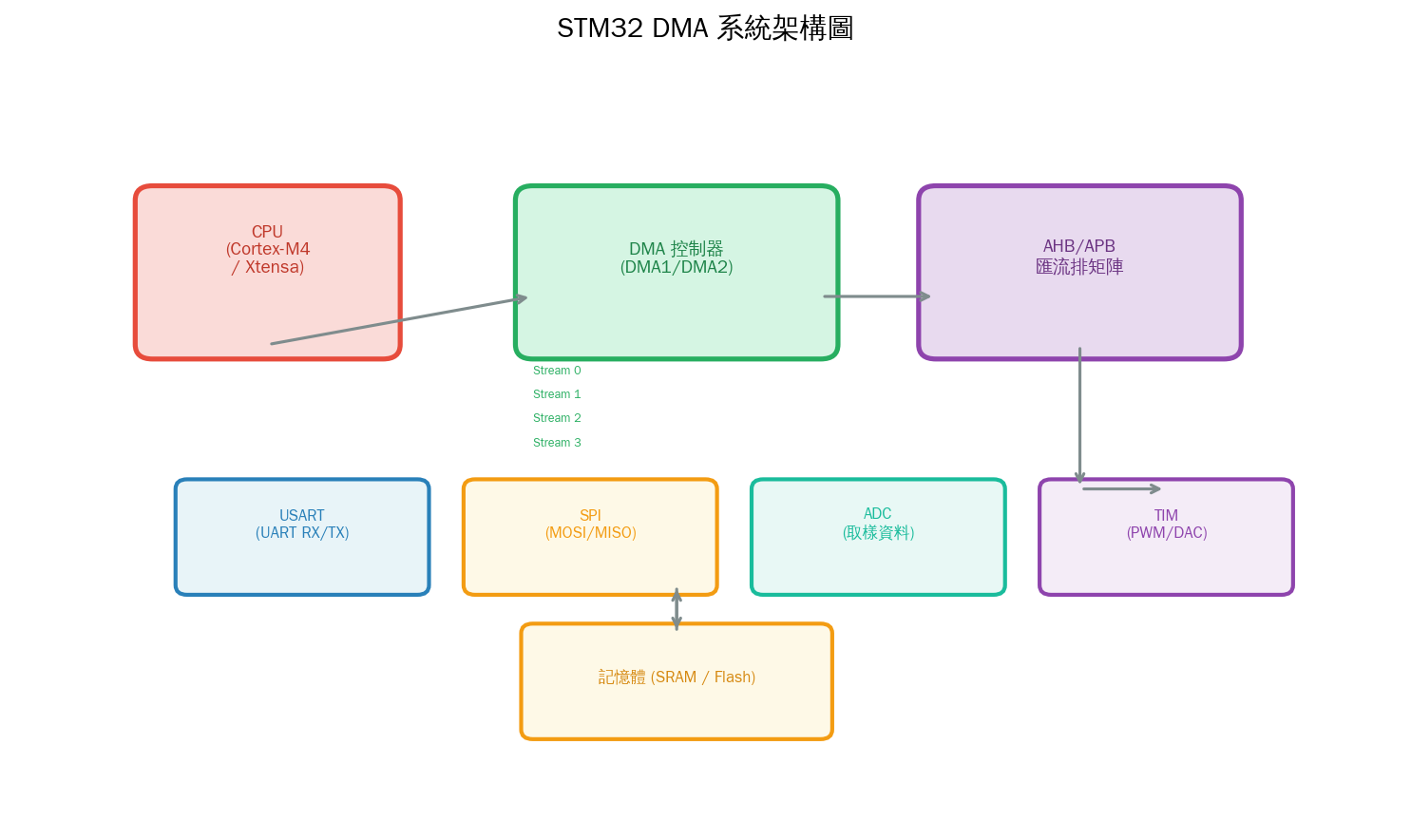
以 STM32F4 為例,DMA2 有 8 個 Stream(資料流),每個 Stream 有 8 個 Channel(通道):
| 元件 | 說明 |
|---|---|
| DMA 控制器 | STM32F4 有 DMA1 和 DMA2,共 16 個 Stream |
| Stream(資料流) | 每個 Stream 管理一組傳輸,可配置優先級 |
| Channel(通道) | 每個 Stream 可選 8 個觸發源之一(如 USART_TX、SPI_RX) |
| FIFO | 每個 Stream 有 4 word FIFO,用於資料寬度匹配 |
| 傳輸計數器 | 每次傳輸遞減,歸零時觸發完成中斷 |
DMA 傳輸類型
- M2M(Memory-to-Memory):記憶體區塊搬運(如 memcpy 的硬體加速)
- M2P(Memory-to-Peripheral):記憶體 → 周邊(如 SPI 發送、DAC 輸出)
- P2M(Peripheral-to-Memory):周邊 → 記憶體(如 ADC 取樣、UART 接收)
- P2P(Peripheral-to-Peripheral):周邊直連(部分系列支援)
DMA 請求/確認握手機制

當周邊(如 USART)的 RX 寄存器收到一個字節後:
- 周邊拉高 DMA Request 訊號
- DMA 控制器仲裁(優先級 + 輪詢機制)
- DMA 回傳 Ack,取得匯流排控制權
- DMA 從周邊資料寄存器讀取資料,寫入記憶體位址
- 位址遞增、計數器遞減
- 釋放匯流排,等待下一次 Request
Ping-Pong Buffer(雙緩衝)

Ping-Pong Buffer 是最經典的 DMA 優化技巧:使用兩個 Buffer 輪流由 DMA 寫入和 CPU 處理。DMA 正在寫入的 Buffer 不會被 CPU 讀取,CPU 正在處理的 Buffer 不會被 DMA 覆寫。
實作重點:
- DMA 完成中斷中切換 Buffer 指標
- 兩個 Buffer 大小必須相同
- 使用 Circular Mode 或雙 Buffer Mode(STM32 部分系列支援硬體自動切換)
STM32 HAL 實作:DMA + ADC 連續取樣
#include "stm32f4xx_hal.h"
#define ADC_BUF_LEN 1024
uint16_t adc_buffer[ADC_BUF_LEN];
ADC_HandleTypeDef hadc1;
DMA_HandleTypeDef hdma_adc;
void MX_DMA_Init(void) {
__HAL_RCC_DMA2_CLK_ENABLE();
hdma_adc.Instance = DMA2_Stream0;
hdma_adc.Init.Channel = DMA_CHANNEL_0;
hdma_adc.Init.Direction = DMA_PERIPH_TO_MEMORY; // P2M
hdma_adc.Init.PeriphInc = DMA_PINC_DISABLE; // 周邊位址不遞增
hdma_adc.Init.MemInc = DMA_MINC_ENABLE; // 記憶體位址遞增
hdma_adc.Init.PeriphDataAlignment = DMA_PDATAALIGN_HALFWORD; // 16 bit
hdma_adc.Init.MemDataAlignment = DMA_MDATAALIGN_HALFWORD;
hdma_adc.Init.Mode = DMA_CIRCULAR; // 循環模式
hdma_adc.Init.Priority = DMA_PRIORITY_HIGH;
HAL_DMA_Init(&hdma_adc);
__HAL_LINKDMA(&hadc1, DMA_Handle, hdma_adc);
}
void MX_ADC1_Init(void) {
hadc1.Instance = ADC1;
hadc1.Init.ScanConvMode = DISABLE;
hadc1.Init.ContinuousConvMode = ENABLE; // 連續轉換
hadc1.Init.ExternalTrigConv = ADC_SOFTWARE_START;
hadc1.Init.NbrOfConversion = 1;
HAL_ADC_Init(&hadc1);
}
int main(void) {
HAL_Init();
MX_DMA_Init();
MX_ADC1_Init();
// 啟動 DMA + ADC(硬體自動搬運)
HAL_ADC_Start_DMA(&hadc1, (uint32_t*)adc_buffer, ADC_BUF_LEN);
while (1) {
// CPU 可以在這裡做其他事!
// 最新的 ADC 資料一直在 adc_buffer[] 中更新
uint16_t latest = adc_buffer[ADC_BUF_LEN - 1];
HAL_Delay(10);
}
}
// DMA 完成回呼(每填滿一次觸發)
void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc) {
// 可在此切換 Ping-Pong Buffer
// HAL_ADC_Start_DMA(&hadc1, (uint32_t*)ping_buffer, ADC_BUF_LEN);
}ESP32 實作:DMA + SPI 傳輸
ESP32 的 SPI 控制器內建硬體 DMA(GDMA),支援自動發送/接收大量資料:
#include "driver/spi_master.h"
#define DMA_CHUNK_SIZE 4096
uint8_t tx_buffer[DMA_CHUNK_SIZE];
uint8_t rx_buffer[DMA_CHUNK_SIZE];
void app_main(void) {
spi_bus_config_t bus_cfg = {
.miso_io_num = 12,
.mosi_io_num = 13,
.sclk_io_num = 14,
.quadwp_io_num = -1,
.quadhd_io_num = -1,
.max_transfer_sz = DMA_CHUNK_SIZE * 2,
};
spi_bus_initialize(SPI2_HOST, &bus_cfg, SPI_DMA_CH_AUTO); // 啟用 DMA
spi_device_handle_t spi;
spi_device_interface_config_t dev_cfg = {
.clock_speed_hz = 10 * 1000 * 1000, // 10 MHz
.mode = 0,
.spics_io_num = 15,
.queue_size = 1,
};
spi_bus_add_device(SPI2_HOST, &dev_cfg, &spi);
// DMA 傳輸(資料自動透過 GDMA 搬運,不佔用 CPU)
spi_transaction_t t = {
.length = DMA_CHUNK_SIZE * 8, // 位元數
.tx_buffer = tx_buffer,
.rx_buffer = rx_buffer,
};
spi_device_transmit(spi, &t); // 底層使用 DMA 傳輸
// 同時,CPU 可以處理其他任務
printf("SPI DMA 傳輸完成!\n");
}DMA + FIFO 的搭配
DMA 和 FIFO 是天生一對。DMA 負責資料搬運,FIFO 負責速率匹配和數據緩衝:
- UART RX:DMA 將 UART FIFO 的資料週期性搬入 Ring Buffer,CPU 從 Ring Buffer 讀取
- SPI TX:CPU 填充 DMA Buffer,DMA 逐 byte 餵給 SPI FIFO,CPU 完全解放
- ADC + DMA + 雙 Buffer:DMA 輪流填充兩個 Buffer,CPU 處理已填滿的 Buffer
實務上,DMA 觸發來源通常設定為周邊 FIFO 的「幾乎空」或「幾乎滿」事件,而非每個 byte 都觸發,這樣可以大幅降低 DMA 傳輸次數。
常見陷阱
Cache Coherency(快取一致性)
這是 STM32H7 等高階 MCU 最常見的問題。CPU 的 Cache 中可能有資料的舊副本,而 DMA 直接寫入了 SRAM——CPU 讀到的可能是 Cache 中的舊資料。
解法:使用 DMA 緩衝區所在的記憶體區域配置為「非快取」(Non-Cacheable),或在訪問前執行 Cache 清理/失效操作。
// STM32H7 解法:使用非快取記憶體區段
// 或在 DMA 讀取前失效 Cache
SCB_InvalidateDCache_by_Addr((uint32_t*)buffer, size);
// 在 DMA 寫入前清理 Cache
SCB_CleanDCache_by_Addr((uint32_t*)buffer, size);Buffer Overflow / Underflow
DMA 傳輸速度超過 CPU 處理速度時,Buffer 會被覆寫(Overflow)。反之,CPU 處理太快導致 Buffer 空(Underflow)。
解法:使用 Ping-Pong Buffer + 水位標記(Watermark),或使用 Circular DMA Mode + 讀取/寫入指標追蹤。
DMA 與中斷競爭
DMA 傳輸完成中斷和其他中斷同時發生時,可能導致資料競爭(Race Condition)。
解法:在 DMA 回呼中使用原子操作或關閉中斷來保護共享資料。
總結
DMA 是嵌入式系統中與 Timer、Interrupt 並列的三大核心硬體資源之一。善用 DMA 可以讓你的系統在同樣的 CPU 頻率下處理更多的資料流,這是從「能用」到「高效能」的關鍵技術。
初學者建議從 STM32 HAL 的 ADC + DMA 範例開始,觀察 DMA 如何讓 CPU 從輪詢中解放。進階後再挑戰 Ping-Pong Buffer 和快取一致性問題。
📖 延伸閱讀:FIFO 完全解析 · Modbus 通訊協定 · PID 演算法

文章評論